In this blog we will often talk about generative text AI. Since each performant generative text AI belongs to the deep learning domain, this means we need to talk about artificial neural networks. Artificial neural networks (ANNs) are a type of machine learning model that are inspired by the human brain. They consist of layers of interconnected nodes or “neurons”:
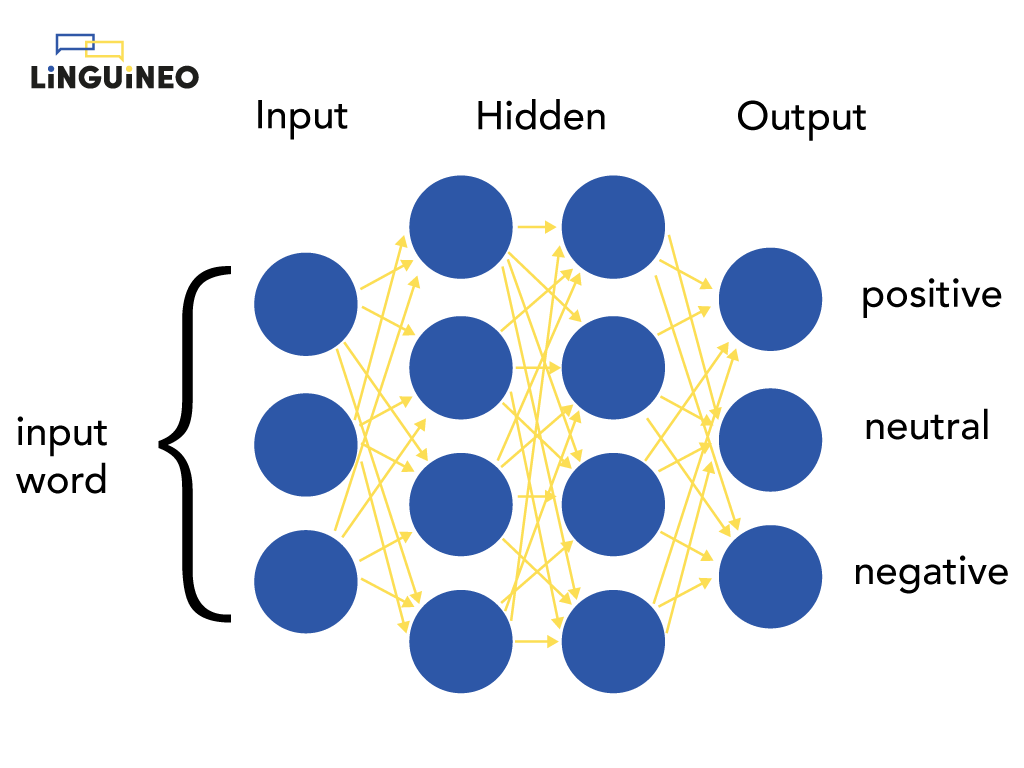
The neural network on the picture determines for a word whether it has a positive, neutral or negative connotation. It has 1 input layer (that accepts the input word), 2 hidden layers (=the layers in the middle) and 1 output layer (that returns the output).
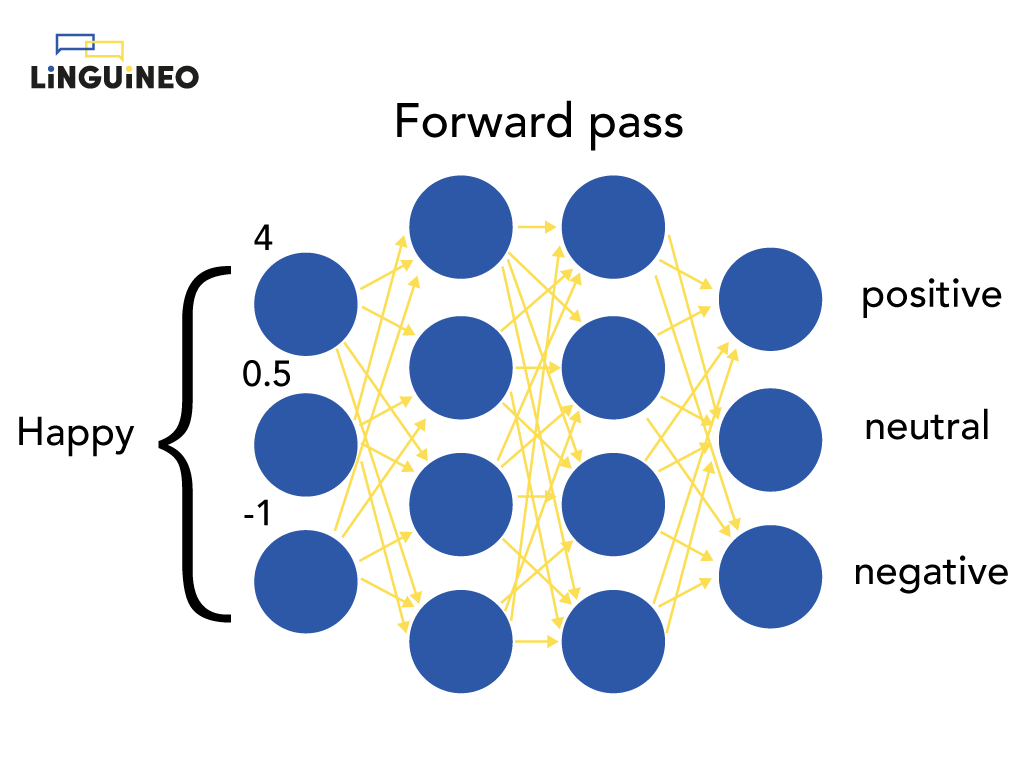
A neural network makes predictions by processing and transmitting numbers to each next layer. The input word is transmitted to the nodes of the first hidden layer, where some new numbers are calculated that are passed to the next layer. To calculate these numbers, the weights of each connection are multiplied with the input values of each connection after which another function (like sigmoid in the example) is applied to keep the passed numbers in a specific range. It are these weights that steer the calculations. Finally, the numbers calculated by the last hidden layer are transmitted to the output layer, and determine what the output is. For our example, the end result is 0.81 for positive, 0.02 for negative and 0.19 for neutral, indicating that the neural network predicts this word should be classified as positive (since 0.81 is the highest):
Technical notes for Xavier
In the above animation, we do not explain why we represent the word “happy” with the numbers [4, 0.5, -1] in the input layer. We just ignore how to represent a word to the network for now – the important thing to get is the word is represented to the network as numbers. How we represent a word as numbers, we will cover later.
Also, the ANN above returns a probability distribution. ANNs almost work always like this. They never say “this is the exact output”, it is almost always a probability over all (or a lot of) the different options.
Training a neural network
How does the neural network know which calculations to perform in order to achieve a correct prediction? We can’t easily make up any rules or do calculations some traditional way to end up with a correct probability distribution (when working with unstructured data such as a piece of text, an audio fragment or an image).
Well, the weights of the first version of a neural network are actually entirely wrong. They are initialized randomly. But by processing example after example and using an algorithm called backpropagation it knows how to adjust its weights to get closer and closer to an accurate solution.
This process is also called the training of the neural network. In order for this to work, the network needs to know the correct output value for each training example. Without it, it couldn’t calculate its error and never adapt its weights towards the correct solution. So for our example above we need (word -> classification) pairs as training data, like (happy: positive = 1; neutral = 0, negative = 0), to feed to the network during training. For other ANNS this will be something different. For speech recognition for example, this would be (speech fragment -> correctly transcribed text) pairs.
If you need to have this training data anyway, why do you still need the neural network? Can’t you just do a lookup on the training data? For the examples you have you can do such lookup, but for most problems for which ANNs are used, no example is ever unique and it is not feasible to collect the training data for all possible inputs. The point is that it learns to model the problem in its neurons, and it learns to generalize, so it can deal with inputs it didn’t see at training time too.
Small, big or huge AI models
You will hear people talk about small, big or huge AI models.
This size of an AI model refers to the number of parameters an artificial neural network has. A parameter is really just one of the weights you saw before (note for the purists: we are omitting the bias parameters here; and we are also not covering the hyper parameters of the network which is something entirely different). Small ANN student assignments involve neural networks with only a few parameters. Many production language related ANNs have about 100M parameters. The OpenAI GPT3 model has reportedly 175 billion parameters.
The number of parameters is directly linked to the computational power you need and what the ANN can learn. The more parameters, the more computation power you need and the more different things your ANN can learn. Especially the GPT3-model’s size spans the crown: to store the parameters alone, you need 350 GB! To store all the textual data of Wikipedia you only need 50GB. This gives a sense of its ability to store detailed data, but it also gives an impression of how much computational power it needs compared to other models.
Transfer learning
A popular thing to do – in the AI community (haha Xavier, I preempted you there!) – is to use transfer learning:
To understand how transfer learning works you can think of the first hidden layers of an ANN as containing more general info for solving your problems. For language models, the first layers could represent more coarse features, such as individual words and syntax, while later layers learn higher level features like semantic meaning, contextual information and relationships between words. By only removing the last layers of the network, you can use the same network for different tasks without having to retrain the entire network.
This means that larger models can be retrained for a particular task or domain by only retraining only the last layers, which is much less computationally expensive and requires in general much less training data (often a few thousand training samples are enough as opposed to millions). This makes it possible for smaller companies or research teams with less budget to do stuff with large models and democratizes AI models to a wider public (since the base models are usually extremely expensive to train).