Generative text AI is AI – an ANN, either a recurrent neural network or a transformer – that produces continuous text. Usually, the base general task on which these systems are trained is “next word prediction”, but it can be anything. Translating a text, paraphrasing a text, correcting a text, making a text easier to read, predict what came before instead of after,…
Oversimplified, generative text AI is next word prediction. When you enter a prompt in ChatGPT or GPT4 like “Write me a story about generative text AI.” it generates the requested story by predicting word after word.
Technical note for Xavier
To make generative AI work well, <START> and <END> tokens are usually added to the training data to teach them to determine the beginning and ends of something. Recent models also incorporate human feedback on top to be more truthful and possibly less harmful. And on top of next word prediction, in-between word prediction or previous word prediction can also be trained. But disregarding the bit more complex architectures and other options these systems are always just predicting word after word without any added reasoning on top whatsoever.
The basic idea behind generative text AI is to train the model on a large dataset of text, such as books, articles, or websites, to make it predict the next word. We don’t need labeled data for this since the “next word” is always available in the sentences of the texts themselves. When we don’t need human labelled data we talk about “unsupervised learning”. This has a huge advantage. Since there exist trillions of sentences available for training, the access to “big data” is easy.
If we want to visualize such an ANN on a high level, it looks something like this:
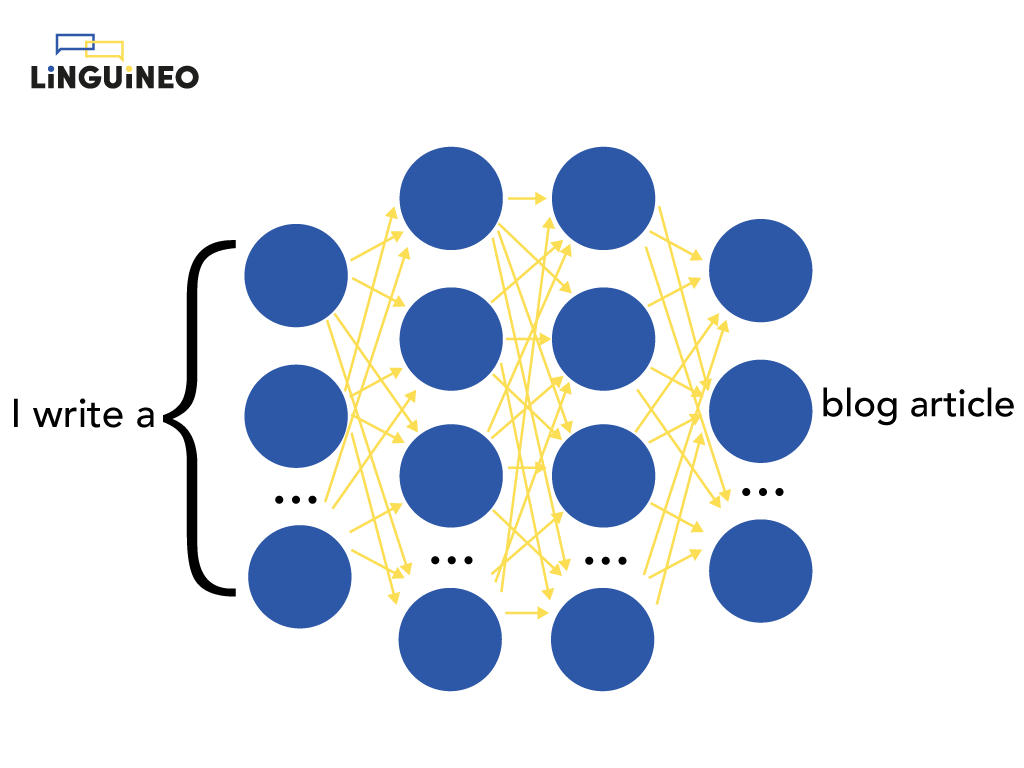
This is only a high level representation. In reality, the most state-of-the-art architecture of these systems – the transformer – is quite complex. We already mentioned transformers in the previous section when we were talking about the encoder that produces the contextual embeddings. As we showed there, it is able to process text in a way that is much more complex and sophisticated than previous language models.
The intuition about it is that:
- by considering the surrounding words and sentences of a word, it is much better at understand the intended meaning
- it works in a “bidirectional” manner – it can understand how the words in a sentence relate to each other both forwards and backwards, which can help it to better understand the overall meaning of a piece of text.
Technical note for Xavier
This transformer architecture actually consists of both an encoder (e.g. “from static word embeddings to contextual embeddings”) and a decoder (e.g. “from contextual embeddings of encoder and its own contextual embeddings to target task output”). The encoder is bidirectional, the decoder is unidirectional (only looking at works that come after, not before). The explanation of this system is quite complex and there are many variants that all use the concept of contextual semantic embeddings / self attention. The GPT models are actually called “decoder-only” since they are only using the decoder part of a typical transformer although “modified encoder only” would be a more suitable name imho. This video is a good explanation of Transformers – it’s one of the most clear videos explaining the current generative text AI breakthroughs. Following up on that, the blog article “The Illustrated Transformer” explains the transformer even more in-depth. And if you want to dig even deeper, this video explains how a transformer works at both training and inference time. Some more technical background is required for these though.
The task a system like this learns is “next word prediction”, not “next entire phrase prediction”. It can only predict one word at a time. So the ANN is run in different time steps, predicting the first next word first, then the second, and so on.
Like we mentioned before, the output for each run is again a probability distribution. So, for instance, if you feed the ANN the sentence “I am working”, the next word with the highest probability could be “in”, but it could be closely followed by “at” or “on”. 1 option is selected then.
Technical notes for Xavier
This doesn’t really need to be the word with the highest probability – all implementations allow a configuration option to pick either the word with the highest probability or allow some freedom in this. Once the word is picked, the algorithm continues with predicting the next word. It goes on like this until a certain condition is met, like maximum tokens reached or a something like a <STOP> token is encountered (which is a “word” the model learned at training time to know when to stop).
An important thing here to realise is the simplicity of the algorithm. The only thing it is really doing – albeit with “smart meaningful word and in-sentence relationship representations” the transformer is providing – is predicting the next word given some input text (“the prompt”) based on a lot of statistics.
1 cool thing about this generative text AI is that it doesn’t need to necessarily predict the next word. You can just as easily train it for “previous word prediction” or “in-between word prediction” – something that would be much more difficult for humans. You could pass it “Hi, here is the final chapter of my book. Can you give me what comes before.” – it would work just as well as the other way around.
