In the article about artificial neural networks we gave some high level representation of what such a neural network is. The deeper you dig into these neural networks, the more details you encounter, like why it often makes sense to prune nodes, or that there are several kinds of neurons some of which keep different “states”. Or that there are even very different kinds of neural network layers, and complex architectures consisting of multiple neural networks communicating with each other. But we will just focus on one question now specifically for language related ANNs.
Let’s get back to the neural network we talked about before:
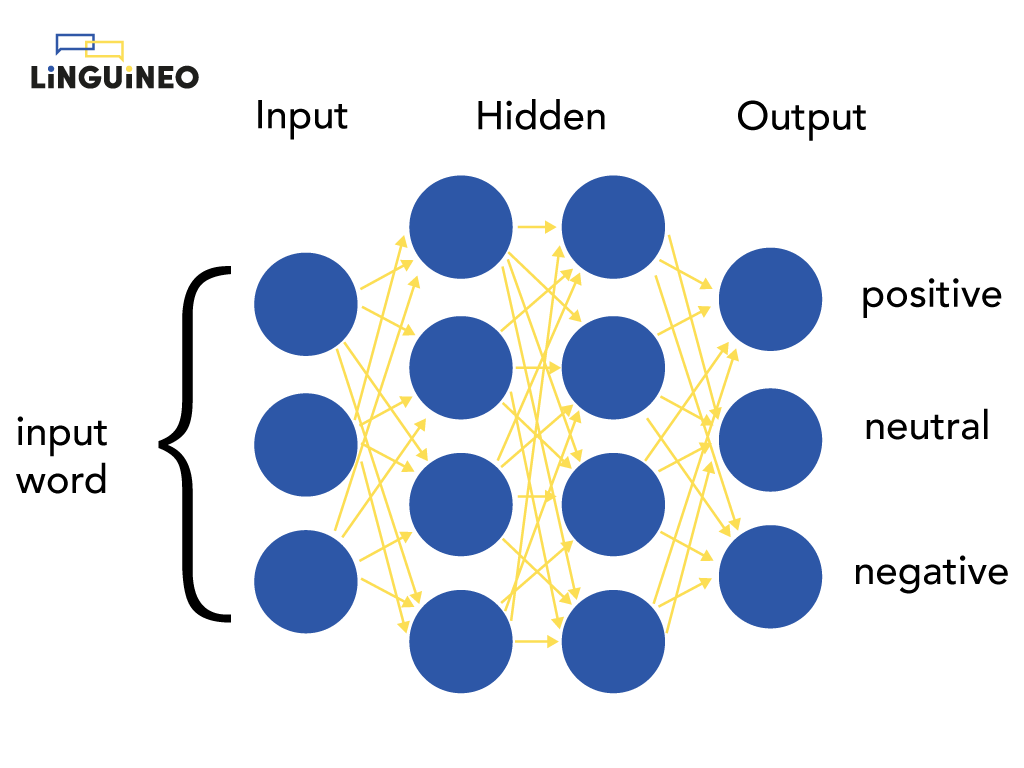
In the example with the calculations we presented the input word “happy” as [4, 0.5, -1] to demonstrate how a neural network works. Of course, this representation of the word happy was entirely made up and wouldn’t work in a real setting. So then, how do we represent a word?
1. Naive approach: take no semantic information into account
A natural reflex would be: what kind of question is that? By its letters of course. You represent the word “word” with “word”. Simple! Well, it’s not. A machine only understands numbers so we need to convert the word into numbers. So what is a good way to do this ?
To convert a word to numbers, a naive approach is to create a dictionary with each known word (or word part), and give each word a unique number. The word “horse” could be number 1122 and the word “person” could be number 1123.
| TOKEN | INDEX |
|---|---|
| aardvark | 0 |
| … | |
| horse | 1122 |
| person | 1123 |
| … |
Technical note for Xavier
I’m taking a shortcut here: you actually need to convert the actual numbers to their one hot vector encodings first in order for this approach to work. Otherwise a relationship between words or letters is created that is just not there, e.g. “person” almost being the same as “horse” because their numbers are almost the same.
For many problems, such as predicting a next word or translating the next word in a sentence, it turns out the above approach does not work well. The important piece of the puzzle here is that this approach fundamentally lacks the ability to relate words to each other in a semantic way.
2. Better approach: take static semantic information into account
Let’s consider the words “queen” and “king”. These words are very similar semantically – they basically mean the same thing except for the gender. But in our approach above the words would be entirely unrelated to each other. This means that whatever our neural network learns for the word “queen” it will need to learn again for the word “king”.
But we know words share many characteristics with other words – it doesn’t make sense to treat them as entirely separate entities. They might be synonyms, opposites, belong to the same semantic domain, have the same grammatical category,… Seeing each word as a standalone unit, or even just as the combination of its letters, is not the way to go – it certainly isn’t how a human would approach it. What we need is a numeric semantic representation that takes all these relations into account.
How do we get such semantic word representations?
The answer is: with an algorithm that’s based on which words appear together in a huge set of sentences. The details of it don’t matter. If you want to know more read about Word2Vec and GloVe, and word embeddings. Using this approach we get semantic representations of a word that capture its (static) meaning.
The simplified representations could be:
Queen: [-0.43 0.57 0.12 0.48 0.63 0.93 0.01 … 0.44]
King: [-0.43 0.57 0.12 0.48 -0.57 -0.91 0.01 … 0.44]
As you may notice, this representation of both words is the same (they share the same numbers), except for the fifth and sixth values, which might be linked to the different gender of the words.
Technical note for Xavier
Again we are simplifying – in reality the embeddings of 2 such related words are very similar but never identical since training of an AI system never produces perfect results. The values are also never human readable; you can think of each number representing something like gender, word type, domain,…but when they are trained by a machine it is much more likely the machine comes up with characteristics that are not human readable, or that a human readable one is spread over multiple values.
It turns out that for tasks in which semantic meaning is important (such as predicting or translating a next word) capturing such semantic relationships between words is of vital importance. It is an essential ingredient to make tasks like “next word prediction” and “masked language modelling” work well.
Although there are much more semantic tasks, I’m mentioning “next word prediction” and “masked language modelling” here because they are the primary tasks most generative text ai models are trained for.
“Next word prediction” is the task of predicting the most likely word after a given phrase. For example, for the given phrase “I am writing a blog” such a system would output a probability distribution over all possible next word (parts) in which “article”, “about” or “.” are probably all very probable.
“Masked language modelling” is a similar task but instead of predicting the next word, the most likely word in the middle of a sentence is predicted. For a phrase like “I am writing a <MASK> article.” it would return a probability distribution over all possible words at the <MASK> position.
Technical note for Xavier
These word embeddings are a great starting point to get your hands dirty with language related machine learning. Training them is easy – you don’t need tons of computational power or a lot of annotated data.
They are also relatively special in the sense that when training them, the actual output that is used are the weights, not the output of the trained network itself. This helps to get some deeper intuition on what ANN weights and their activations are.
They also have many practical and fun applications. You can use them to query for synonyms for another word or for a list of words for a particular domain. By training them yourself on extra texts you can control which words are known within the embeddings and for example add low frequent or local words (very similar words have very similar embeddings). They can also be asked questions like “man is to computer programmer what woman is to …”. Unfortunately, their answer in this case is likely to be something like “housewife”. So they usually contain a lot of bias. But it can be shown you can actually remove that bias once it is found despite word embeddings being unreadable by themselves.
3. Best approach: take contextual semantic information into account
However, this is not the end of it. We need to take the representation one step further. These static semantic embeddings we now have for each word are great, but we are still missing something essential: each word actually means something slightly different in each sentence.
A clear example of this are the sentences “The rabbit knew it had to flee from the fox” and “The fox knew it could attack the rabbit”. The same word “it” refers to 2 completely different things: one time the fox, one time the rabbit, and it’s in both cases essential info.
Although “it” is an easy to understand example, the same is true for each word in a sentence, which is a bit more difficult to understand. It turns out modelling the relationship of each word with all the other words in a sentence gives much better results. And our semantic embeddings do not model relationships like that – they don’t “look around” to the other words.
So, we do not only need to capture the “always true” relationships between words such as that king is the male version of queen, but also the relationships between words in the exact sentences we use them in. The first way to capture such relationships was to use a special kind of neural networks – recurrent neural networks – but the current state-of-the-art approach to this is using a transformer, which has an encoder that gives us contextual embeddings (that are based on the static ones) as opposed to the non-contextual ones we discussed in the previous section.
This approach – first described in the well referenced paper “Attention is all you need” – was probably the most important breakthrough for GPT3, ChatGPT and GPT4 to work as well as they do today.
Moving from a static semantic word representation to a contextual semantic word representation was the last remaining part of the puzzle when it comes down to representing a word to the machine.